Golang 语言基础学习笔记
Apr 19, 2024 · 110min
本文主要记录博主 Go 语言的学习过程和结果,参考 Golang中文学习文档,本文不保证内容的原创性
Golang 是一个固执己见且叛逆的孩子,很多语法都反其道而行之让人无语至极
准备开始
MacOS(Linux) 通过 brew 包管理器安装 golang,安装完后基本就已经可以了
brew install go博主使用 VsCode 作为开发工具,因为我已经完成 VsCode 个性化配置,故而使用我所熟悉的编辑器,除了 VsCode,也可以使用 GoLand。以下列表为 VsCode 所依赖的插件,其它内容请查看 Use
- Go - Golang 官方团队开发的 VsCode 插件
通过快捷键 Shift + Command + P 打开命令面板,输入 > Go: Install/Update Tools
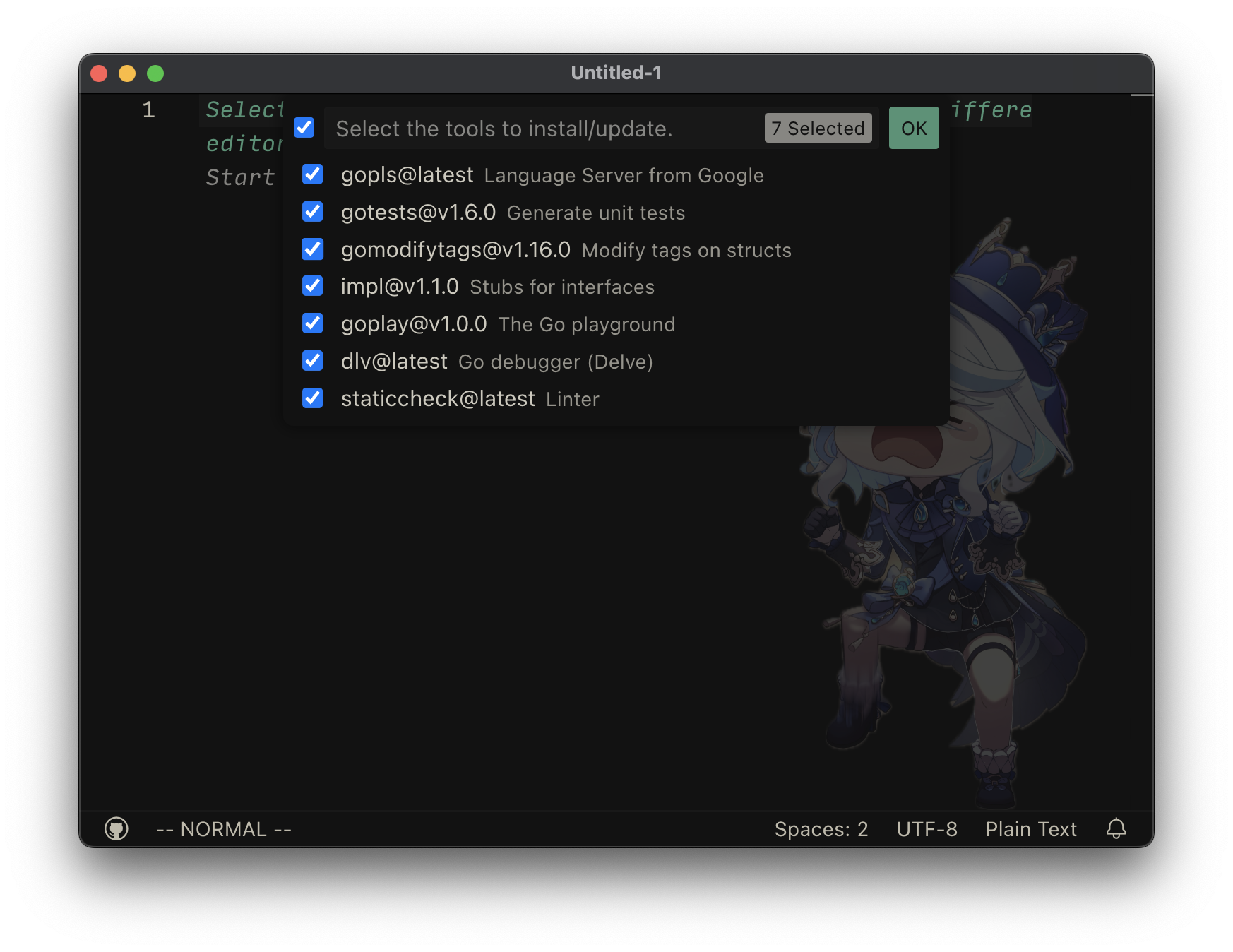
选择后会弹出以下面板,选中所有的 go tools 后点击 OK 按钮或者 Enter 键
在安装时可能会因为网络原因导致安装错误,此时我们需要设置代理。
go env -w GO111MODULE=on
go env -w GOPROXY=https://goproxy.io,direct设置后需要重启 Vs Code 然后重复以上操作安装即可,可能需要一些时间。到此编辑器基本配置完毕可以开始写代码了。
数组
数组可以存放多个同一类型的数据,数组也是一种数据类型,在 Go 中,数组是值类型而非引用,并不是指向头部元素的指针。并且在数组初始化时声明长度只能是一个常量而不能使用变量
// 这是正确的
var a = int[5]
// 这是错误的
var capacity = 5;
var b = int[capacity]如果事先知道数据长度,且后续使用时不会有扩容需求,那么可以考虑使用数组去存储这一组数据。
例如有这么一个需求,需要求 10、2、3、4.0、50 这些数的平均值,我们可以这么做:
func main() {
num1 := 10.0
num2 := 2.0
num3 := 4.0
num4 := 50.0
sum := num1 + num2 + num3 + num4
avg := sum / 4
println("avg =", avg)
}这或许看不出什么问题,但是如果再加一个需求,我的值可能是动态输入,且数量可能不同,很好,显然上面的代码不能做到。这时候我们可以使用数组来完成。
注意:在 Go 中,声明一个数组语法是 []T
很显然,下面用数组实现的功能更强大,通过 calc 方法求和之后将值返回,可以使用 fmt.Printf 打印这个值,注意这里的 %.2f 是保留几位小数的意思!
func main() {
avg := calc([]float64{10, 2, 4, 50, 60, 70, 80})
fmt.Printf("avg =%.2f", avg)
}
func calc(list []float64) (avg float64) {
var sum = 0.0
for _, num := range list {
sum += num
}
return sum / float64(len(list))
}使用
- 数组可以通过下标进行取值,和其他编程语言一样,下标是从 0 开始。
- 要声明一个数组,可以通过语法
[]T来声明,若需要指定数组的长度,那么可以使用[6]T来声明一个定长的数组。通过[]T{xxx, xxx, xx}来初始化一个数组。 - 数组只能存放同类型的数据,例如
int,你指定一个[]int后,你不能再往这个数组里存入其他类型,例如:[]int{1.34}这是不允许的。
在数组中通过下标进行取值,例如
var arr = []int{1, 2, 3}
fmt.Println(arr[0])修改数组指定下标元素
var arr = []int{1, 2, 3}
arr[1] = 9还可以通过内置函数来获取数组中的元素数量
var arr = []int{1, 2, 3}
len(arr) // 3同样可以使用内置函数来访问数组容量,数组的容量等于数组的长度,容量对切片才有意义。
var arr = []int{1, 2, 3}
cap(arr) // 3数组内存布局
数组是一种数据类型,也是一种数据结构,它的优点是能够快速的进行读和写操作。对于删除和新增操作,他是比较慢的。因为数组每一个元素的内存地址它都是连续的。假设第一个元素是 0x08 那么第二个元素必然是 0x10 第三个是 0x18 以此类推...
注意:以上 0x08 中的 8 是根据你这个数组的类型所占用的空间大小来计算的,例如数组类型是 []int 一个 int 类型占 8 个字节,所以内存地址需要加8,如果是 int32 那么内存地址是加 4 或者是 string 那么内存地址需要加 16以此类推
所以我们在通过数组下标取值的时候,实际上就是通过第一个数组内存地址和指定的下标值进行计算得出一个目标元素的内存地址。
切割
所谓的切割,其实就是取某个区间的元素。切割数组格式为 arr[startIndex:endIndex] , 切割的区间为左闭右开。注意这不会改变 arr 的值
var arr = []int{1, 2, 3, 4, 5}
fmt.Println(arr[1:]) // [2,3,4,5]
fmt.Println(arr[2:3]) // [3]
fmt.Println(arr[:3]) // [1, 2, 3]类似于 index >= startIndex && index < endIndex
切片
切片可以用来存储未知长度或不定长的数据,且后续使用过程中频繁插入和删除元素。
可以通过一下方法去初始化一个切片
var nums []int // 值
nums := []int{1, 2, 3} // 值
nums := make([]int, 0, 0) // 值
nums := new([]int) // 指针其实数组和切片看起来其实没有什么区别,唯一的区别是在初始化的时候数组需要确定长度而切片则不需要。通常情况下使用 make 来进行创建切片,它接收三个参数:类型、长度和容量。
通过 var nums []int 这种方式声明的切片,默认值为 nil,所以不会为其分配内存,而在使用 make 进行初始化时,建议预分配一个足够的容量,可以有效减少后续扩容的内存消耗。
所谓的切片其实和 Java 中的 ArrayList 是一样的,都可以根据长度和容量进行扩容。
长度和容量的区别是:
-
长度 - 表示当前切片中的数据长度或者说数量
-
容量 - 切片底层数组的最大容量,如果切片容量已满,再次添加时会自动扩容,如果容量小于 256 那么每次扩容都是 capacity * 2 的容量。算法为:
newcap = oldcap+(oldcap+3*256)/4初始长度 增长比例 256 2 512 1.63 1024 1.44 2048 1.35 4096 1.3
切片底层依然是通过数组来实现,但是引用类型,他是一个指向底层数组的指针,在扩容时,会创建一个对应长度的数组,然后将旧数组的数据拷贝过去,此时 Data 指向扩容后的数组
type Slice[T] struct {
Cap: int
Len: int
Data: *T
}切片使用
切片的使用方式和数组基本上是一样的,可以使用 append 实现添加操作,slice 是要添加元素的目标切片,elems 是待添加的元素,返回值是添加后的切片。
func append(slice []Type, elems ...Type) []Type创建一个长度为 0 容量为 0 的空切片,然后通过 append 添加一些元素
nums := make([]int, 0, 0)
nums = append(nums, 1, 2, 3, 4, 5, 6, 7)
fmt.Println(len(nums), cap(nums)) // 7 8 可以看到长度与容量并不一致。插入元素
从头部开始插入元素
nums := []int{1, 2, 3, 4, 5, 6, 7, 8, 9, 10}
nums = append([]int{-1, 0}, nums...) // [-1 0 1 2 3 4 5 6 7 8 9 10]从中间指定位置插入元素
nums := []int{1, 2, 3, 4, 5, 6, 7, 8, 9, 10}
nums = append(nums[:5], append([]int{999, 333}, nums[5:]...)...) // [1 2 3 4 5 999 333 6 7 8 9 10]从尾部插入元素
nums := []int{1, 2, 3, 4, 5, 6, 7, 8, 9, 10}
nums = append(nums, 5645, 4564) // [1 2 3 4 5 6 7 8 9 10 5645 4564]删除元素
从头部删除 n 个元素
n := 2
nums := []int{1, 2, 3}
nums = nums[n:] // [3]从尾部删除 n 个元素
n := 2
nums := []int{1, 2, 3}
nums = nums[0 : len(nums)-n] // [1]从中间指定下标位置开始删除 n 个元素
nums := []int{1, 2, 3, 4, 5, 6}
n := 2
i := 2
nums = append(nums[:i], nums[i+n:]...)删除所有元素
nums := []int{1, 2, 3}
nums = nums[:0] // []拷贝切片
切片在拷贝时,目标切片需要拥有足够的长度
nums := []int{1, 2, 3, 4, 5, 6}
dest := make([]int, 0)
fmt.Printf("nums = %v dest = %v \n", nums, dest) // nums = [1 2 5 6] dest = []
fmt.Printf("copy len = %d ", copy(dest, nums))
fmt.Printf("nums = %v dest = %v \n", nums, dest)
// copy len = 0 nums = [1 2 5 6] dest = []
dest = make([]int, 2)
fmt.Printf("copy len = %d ", copy(dest, nums))
fmt.Printf("nums = %v dest = %v \n", nums, dest)
// copy len = 2 nums = [1 2 5 6] dest = [1 2]
dest = make([]int, len(nums))
fmt.Printf("copy len = %d ", copy(dest, nums))
fmt.Printf("nums = %v dest = %v \n", nums, dest)
//copy len = 4 nums = [1 2 5 6] dest = [1 2 5 6]遍历
切片的遍历方式和数组完全一模一样
nums := []int{1, 2, 3, 4, 5, 6}
for i = 0; i < len(nums); i++ {
fmt.Println(nums[i])
}range 循环
nums := []int{1, 2, 3, 4, 5, 6}
for index, val := range nums {
fmt.Println(index, " ", val)
}拓展表达式
切片和数组都可以使用简单表达式进行切割,但是拓展表达式只能在切片中使用。拓展表达式主要是为了解决切片共享底层数组的读写问题,主要格式为如下,需要满足关系 low<= high <= max <= cap ,使用拓展表达式切割的切片容量为 max-low
slice[low:high:max]low 和 high 依旧是原来的含义而多出来的 max 则是指的是最大容量,例如下面这个例子省略了 max 那么这样创建出来的切片容量就是 len - low
s1 := []int{1, 2, 3, 4, 5, 6, 7, 8, 9} // cap = 9
s2 := s1[3:4] // cap = 9 - 3 = 6由于切片底层数组是一个引用,所以这样切割出来的切片存在一个问题,由于 s1 和 s2 底层共享的是同一个数组,s2 在进行读写的时候会影响到 s1。
s1 := []int{1, 2, 3, 4, 5, 6, 7, 8, 9}
s2 := s1[3:4]
s2 = append(s2, 1)
fmt.Println(s1, s2) // [1 2 3 4 1 6 7 8 9] [4 1]这个问题,可以使用拓展表达式解决,其原理就是将 s2 的容量设置为 1 ,这样在调用 append 的时候会导致容量不足而扩容
s1 := []int{1, 2, 3, 4, 5, 6, 7, 8, 9} // cap = 9
s2 := s1[3:4:4] // cap = 4 - 3 = 1
s2 = append(s2, 1)
fmt.Println(s1, s2) // [1 2 3 4 5 6 7 8 9] [4 1]这个方式只能解决 append 会影响 s1 的问题,如果你 s2[0] = 23 重新赋值,还是会影响到 s1
clear
这个函数是在 Go1.21 中新增的,可以将切片中的值置为零值
arr := []int{1, 2, 3}
clear(arr)
fmt.Println(arr) // [0 0 0]如果是要清空切片,那么可以使用切割的方式并且限制切割后的容量,避免读写时影响原切片的后续元素。
arr := []int{1, 2, 3}
arr = arr[:0:0]
fmt.Println(arr) // []映射表
一般映射表数据结构实现通常有两种,哈希表(HashTable)和搜索树(SearchTree),区别在于前者无序后者有序。在 Go 中,map 的实现是基于哈希桶(也是一种哈希表),所以也是无序的。
初始化
在 Go 中,map 的键类型必须是可比较的,例如string int 是可比较的,而 []int 是不可比较的。初始化 map 有两种方法,第一种是字面量
map[keyType]valueType{}例如
mp := map[string]string{
"name": "CloverYou",
}
mp := map[int]string{
0: "CloverYou",
}第二种方式是使用 make 函数创建,对于 map 类型,它接受不了两个参数,分别是类型和初始容量。
mp := make(map[string]int, 10)
mp := make(map[int]string, 8)map 是引用类型,零值或未初始化的 map 可以访问,但是无法存放元素,所以必须为其分配内存。
var mp1 map[string]string
mp1["name"] = "CloverYou"以上代码抛出一个 panic
panic: assignment to entry in nil map在初始化 map 时应当尽量分配一个合理的容量,以减少扩容次数
访问
访问 map 的方式就像通过索引访问一个数组一样
mp := make(map[string]string, 2)
mp["age"] = "21"
mp["sex"] = "man"
mp["name"] = "CloverYou"
fmt.Println(mp["name"]) // CloverYou
fmt.Println(mp["nickname"]) // ""通过以上代码可以发现,当访问一个不存在的元素 nickname ,依旧会有返回值,map 对于不存在的键会返回对应类型的零值。在访问 map 的时候其实会有两个返回值,第一个是返回对应类型的值,第二个是返回一个布尔值,表示这个键是否存在。
mp := make(map[string]string, 2)
mp["age"] = "21"
mp["sex"] = "man"
mp["name"] = "CloverYou"
nickname, exist := mp["nickname"]
fmt.Println(nickname, exist) // “” false可以使用 len 取 map 的长度
mp := make(map[string]string, 2)
mp["name"] = "CloverYou"
fmt.Println(len(mp)) // 1存值
map 存值的方式和数组一样
mp := make(map[string]int, 2)
mp["age"] = 21
fmt.Println(mp) // map[age:21]如果使用一个已存在的键,那么会覆盖掉原有的值
mp := make(map[string]int, 2)
mp["age"] = 21
fmt.Println(mp) // map[age:21]
if _, exist := mp["age"]; exist {
mp["age"] = 22
}
fmt.Println(mp) // map[age:22]如果使用的是 math.Nan() 作为键的时候,是无法覆盖原有值的。
mp := make(map[float64]string, 10)
mp[math.NaN()] = "Clover You"
mp[math.NaN()] = "My Name"
fmt.Println(mp) // map[NaN:My Name NaN:Clover You]通过结果观察,相同的键并没有被覆盖反而存在多个,这也无法判断其是否存在同时也无法正常取值。
因为NaN是IEE754标准所定义的,其实现是由底层的汇编指令UCOMISD完成,这是一个无序比较双精度浮点数的指令,该指令会考虑到NaN的情况,因此结果就是任何数字都不等于NaN,NaN也不等于自身,这也造成了每次哈希值都不相同
删除
可以通过 delete 函数去删除一个指定的元素
func delete(m map[Type]Type1, key Type)mp := make(map[string]int, 2)
mp["age"] = 21
fmt.Println(mp) // map[age:21]
delete(mp, "age")
fmt.Println(mp) // map[]如果是一个 NaN 键,那么无法删除
遍历 map
可以通过 for range 去遍历 map
mp := map[string]int{
"a": 0,
"b": 1,
"c": 2,
"d": 3,
}
for key, val := range mp {
fmt.Println(key, val)
}以上代码结果
d 3
a 0
b 1
c 2清空 map
Go 1.21 版本之前如果需要清空 map,那么需要遍历去delete
mp := map[string]int {
"a": 0
}
for key := range mp {
delete(mp, key)
}
fmt.Println(mp) // map[]但在 Go1.21 之后和数组一样,可以使用 clear 函数来清空 map 数据。
mp := map[string]int{
"a": 0,
}
clear(mp)
fmt.Println(mp) // map[]Set
Set 是一种无序的,不包含重复元素的集合,Go 没有提供类似的数据结构实现,但是 map 的 key 是无序且不可重复的,可以用 map 来替代 set(类似 Java 中的 HashSet)。
set := make(map[string]struct{}, 10)
set["w"] = struct{}{}
fmt.Println(set) // map[w:{}]使用空结构体不会占用内存
map 不是一个一个内存安全型的数据结构。map 内部有读写检测机制,如果冲突会触发 fatal error ,例如在多线程情况下,读写 map 那么有可能会触发。以下程序就容易引发这个异常
group := sync.WaitGroup{}
group.Add(2)
mp = make(map[string]int, 10)
for i := 0; i < 10; i++ {
go func() {
for i := 0; i < 100; i++ {
mp["age"] = i
}
for i := 0; i < 100; i++ {
fmt.Println(mp["age"])
}
group.Done()
}()
}
group.Wait()fatal error: concurrent map writes可以使用 sync.Map 来解决这个问题
group := sync.WaitGroup{}
group.Add(10)
syncMap := sync.Map{}
for i := 0; i < 10; i++ {
go func() {
for i := 0; i < 100; i++ {
syncMap.Store("age", i)
}
for i := 0; i < 100; i++ {
fmt.Println(syncMap.Load("age"))
}
group.Done()
}()
}
group.Wait()指针
new 和 make
new 和 make 是内置函数,这两个函数有点类似但是也有不同
func new(Type) *Type- 这个函数的返回值是一个指针类型
- 接收一个"类型"参数
- 用于给指针分配内存空间
func make(t Type, size ...IntegerType) Type- 返回值是一个值不是指针
- 接受的第一个参数是一个类型,不定长参数列表根据传入类型的不同而不同
- 用于给切片、映射表、通道分配内存
str := new(string) // string 指针
num := new(int32) // int32 指针
nums := new([]int) // int 切片指针
makeNums := make([]int, 10, 100) // 创基一个长度为10容量为100的int切片
makeMap := make(map[string]int, 10) // 创建一个容量为 10 的映射表
makeChan := make(chan int, 10) // 创建一个缓冲区大小为 10 的通道
>
cd ..